FORTRAN to Rust: part 1
Background
A while ago I got interested in the Voyager space probes, and specifically the image processing that produced pretty pictures of the planets. I thought it would be fun to learn about and reimplement their processing pipeline.
Voyager launched in 1977 and much of their code was written in FORTRAN – a sensible choice at the time. But now it’s the 2020s and I’d much rather use Rust.
One important component is NASA’s SPICE: a set of data formats, tools and APIs for space geometry problems. Data about the trajectory and orientation of many spacecraft, planets, and moons, is publicly available in SPICE format. Voyager pre-dates SPICE but its data was later converted, helping us interpret its raw images.
The SPICE Toolkit is primarily written in FORTRAN 77,
and has an official C translation created with f2c plus some hand-written API wrappers.
There are unofficial bindings for the C library in many languages, including rust-spice.
A sensible person would just use that and get on with the rest of their project.
But calling a complex C API from Rust feels kind of dirty. You lose a lot of Rust’s safety guarantees – misuse of the API might corrupt memory and produce bogus results. Distributing applications is more awkward and less portable since the C library needs to be built and installed separately. And the FORTRAN/C code depends heavily on global state so it’s entirely non-thread-safe. You could make it safe with a big global lock, but some calculations are very expensive and it would be nice to run them in concurrent threads.
So I thought: Why not translate the whole SPICE Toolkit into pure Rust code? And if I’m going to do that, it seems neater to start with the original FORTRAN codebase rather than the ugly f2c-translated C code.
I began with zero knowledge of FORTRAN and ended up essentially writing a FORTRAN compiler
that emits Rust code (f2rust),
which successfully built a half-million-line pure Rust port of the SPICE Toolkit
(rsspice)
that passes the full SPICE test suite.
(Admittedly it’s not a general purpose compiler, it can only compile the SPICE Toolkit,
but it could be extended to support some other FORTRAN programs with only a little more effort.)
This series of posts covers an assortment of interesting or weird or annoying parts of FORTRAN that I learned about, and how I mapped them onto Rust.
 (Raw and processed images from Voyager 1 of Jupiter’s clouds,
C1630903)
(Raw and processed images from Voyager 1 of Jupiter’s clouds,
C1630903)
Introduction to FORTRAN
FORTRAN has evolved a lot since its invention the 1950s. Modern Fortran has lowercase letters and dynamic memory allocation and OOP and so on, making it a much nicer language; but I’m going to ignore most of that. The SPICE Toolkit is written in FORTRAN 77 (X3J3/90.4, standardised in 1978), plus some extensions from MIL-STD 1753, plus a few minor features taken from later standards or non-standard compiler extensions, so that’s all I’m interested in.
Here’s a simple example from SPICE:
C Add two vectors of arbitrary dimension.
SUBROUTINE VADDG ()
C Declarations
IMPLICIT
INTEGER NDIM
DOUBLE PRECISION ( NDIM )
DOUBLE PRECISION ( NDIM )
DOUBLE PRECISION ( NDIM )
C Local variables
INTEGER I
I = 1, NDIM
(I) = (I) + (I)
END DO
RETURN
END
The SUBROUTINE line is straightforward: it’s declaring a subroutine
(i.e. a function with no return value) with the given parameters
(called dummy arguments in FORTRAN).
The dummy argument types are declared later.
NDIM is an INTEGER (typically 32 bits).
V1 is an array of size NDIM, with elements of type DOUBLE PRECISION (typically a 64-bit float).
IMPLICIT NONE is one of the MIL-STD 1753 extensions, and it means every symbol must have a declared type.
Otherwise FORTRAN allows implicit types:
by default any undeclared name that starts with the letter
I, J, K, L, M or N is assumed to be an INTEGER,
and anything else is a REAL (32-bit float).
Hence the old joke: “God is real, unless declared integer.”
You can change the first-letter-based defaults with e.g.
IMPLICIT DOUBLE PRECISION (X-Z). This is, obviously, crazy and error-prone.
Thankfully SPICE consistently uses IMPLICIT NONE to avoid that mess.
DO I = 1, NDIM ... END DO is a simple for loop. It goes from I=1 to I=NDIM, inclusive.
This is also a MIL-STD 1753 extension – without it you’d have to write:
I = 1, NDIM
(I) = (I) + (I)
In that version, the 100 is a statement label.
DO 100 ... will execute every statement up to
(and including) the one labelled 100, then repeat.
CONTINUE is a noop.
We could have put the 100 label
on the VOUT(I) = ... line instead,
but that would make the control flow less clear,
so it’s conventional to end loops with CONTINUE.
If you really want to make your code more confusing, multiple loops can share the same terminal statement label:
I = 1,3
J = 1,3
100 N = N + M(I, J)
which is a nested loop where statement 100 will be executed 9 times.
Going back to the original example, the other peculiar thing (to modern C/Rust programmers) is that the loop starts counting from 1, not 0. That’s because FORTRAN arrays, by default, are indexed from 1. You can also declare an array with arbitrary lower and upper bounds:
INTEGER ( 5 )
INTEGER ( 0: 5 )
INTEGER ( -5: 5 )
The first elements of each array are FOO(1), BAR(0), and BAZ(-5).
The last elements are all index 5.
SPICE uses this to hide some metadata inside certain arrays: the lower bound is declared as -5, while API users should only access index 1 and above, so there’s space to store 6 metadata values (including the array’s capacity and size, allowing a kind of dynamic array API).
Rust translation
f2rust compiles the earlier example into the Rust code:
DummyArray is a wrapper type around &[T] slices that lets you
specify the lower and upper bounds (1..=NDIM) in the constructor.
Accesses to V1[I] will be bounds-checked and mapped onto the corresponding 0-indexed slice element
by DummyArray’s implementation of std::ops::Index.
We set up this mapping at the top of each function and shadow the variable names, so the rest of the code is a pretty direct translation of the original FORTRAN and doesn’t have to worry about the indexing arithmetic.
The DO loop is translated into an idiomatic Rust for in loop.
Some FORTRAN loops can’t be translated as cleanly
(we’ll discuss the details later),
but we special-case the typical simple loops
to keep the generated Rust reasonably concise and readable.
Argument passing
You might notice that in this Rust example, the parameters are a mixture of
pass-by-value (i32), pass-by-reference (&[f64]), and pass-by-mutable-reference (&mut [f64]).
But the FORTRAN code didn’t distinguish these cases.
In FORTRAN, every argument is effectively pass-by-mutable-reference. If you pass a constant or an arithmetic expression as an argument, the compiler will have to store that in RAM (not just in a register) and pass its address into the function.
What’s stopping a FORTRAN function from assigning a value to an argument that is (the address of) a constant? Well, nothing. In C terminology it’s undefined behaviour. If you’re lucky it will crash. If you’re unlucky, who knows. (This is not ideal.)
Since arguments are just addresses, there’s actually very little difference between arrays and scalar values.
You could legally call this VADDG function like:
DOUBLE PRECISION ( 10 )
DOUBLE PRECISION X
X = 2.0D0
CALL ( X, SQRT(2.0D0), 1, (5) )
where the inputs are a scalar X and an arithmetic expression –
both interpreted as arrays of size 1 –
and the output is written to a slice of RES with size 1 starting at the 5th element.
(In case you’re wondering,
2.0D0 is the syntax for a DOUBLE PRECISION constant with value 2.0,
following the same pattern as 2.0E0 for a REAL constant.
2.0 with no exponent is always a REAL.)
What’s stopping you passing NDIM=2 and interpreting the scalars as arrays of size 2?
Again, nothing. It’ll probably read some bogus value from memory and/or crash.
This is one of the biggest challenges when translating to Rust, because Rust really cares about saving you from that kind of bug. We need to conjure up the extra information that Rust’s type system expects, so it can statically prove these bugs won’t occur.
But before getting into further details of the compiler, we should go back to the start.
Fixed source form
FORTRAN was originally designed for punched cards, not interactive terminals, and its syntax reflects that.
 (photo by Arnold Reinhold on Wikimedia;
CC BY-SA 2.5)
(photo by Arnold Reinhold on Wikimedia;
CC BY-SA 2.5)
Each card corresponds to a single line of code, and each column corresponds to a single character (printed at the top of the card for reference). Digits are encoded by punching a single hole in the corresponding number. Uppercase letters and punctuation characters are encoded with two or three holes in a column. Lowercase letters were a luxury they deemed unnecessary. (See further details on the encoding.)
In this photo, the card has 80 columns, but the last 8 are reserved for “identification”. They might be used for a program name and card number, so if you drop a big stack of cards you can put them into a card sorting machine and fix your mess. A FORTRAN compiler will only look at the first 72 columns and ignore the rest.
The first 5 columns are labelled as “statement number”.
These are the numbers used as targets for DO 100 I = ... loops, GO TO 200, etc.
Comment lines are encoded with a C or * character in column 1.
The compiler will ignore the rest of the line.
Column 6 is the “continuation” marker. If your statement doesn’t fit in a single 72-character line, you can get a second card and put any non-zero character in column 6, and it will be treated as a continuation of the previous line. You can have up to 19 continuation lines for one statement; any more than that and you should probably rethink your code.
That leaves only columns 7 to 72 for the actual code. One quirk that lets you squeeze more code onto each card is that almost all whitespace is optional, including whitespace around keywords. Our earlier example could be written as:
(V1,V2,NDIM,VOUT)
IMPLICITNONE
INTEGERNDIM
(NDIM)
(NDIM)
(NDIM)
INTEGERI
DOI=1,NDIM
(I)=(I)+(I)
ENDDO
RETURN
END
I mean, it shouldn’t be written like that, but it could be.
(The original motivation was that whitespace often got missed or miscounted when transcribing handwritten text onto punched cards, so it was safer to make whitespace insignificant; plus it would “enable programmers to arrange their programs in a more readable form” (source, p170), though of course it also enables the opposite, and experience proves you shouldn’t trust programmers.)
FORTRAN 77 source files on a modern computer follow exactly the same format as these old punched cards. Fortran 90 introduced the free source form, which is a lot more modern – you don’t need to indent every line by 6 spaces, lines can be longer, comments can be placed anywhere, etc. But for F77 we need to stick with the old fixed source form.
The first step in f2rust is to parse this syntax:
recognise comments, statement labels, continuation lines,
and canonicalise the code by removing all space characters
and converting lowercase to uppercase (outside of string literals).
Grammar
The next step in the compiler is to parse the FORTRAN statement grammar. FORTRAN 77 doesn’t have a formal grammar specification; it’s defined with a mixture of relatively informal ‘metalanguage’ and prose, and there’s also an appendix with helpful railroad diagrams that are approximately correct.
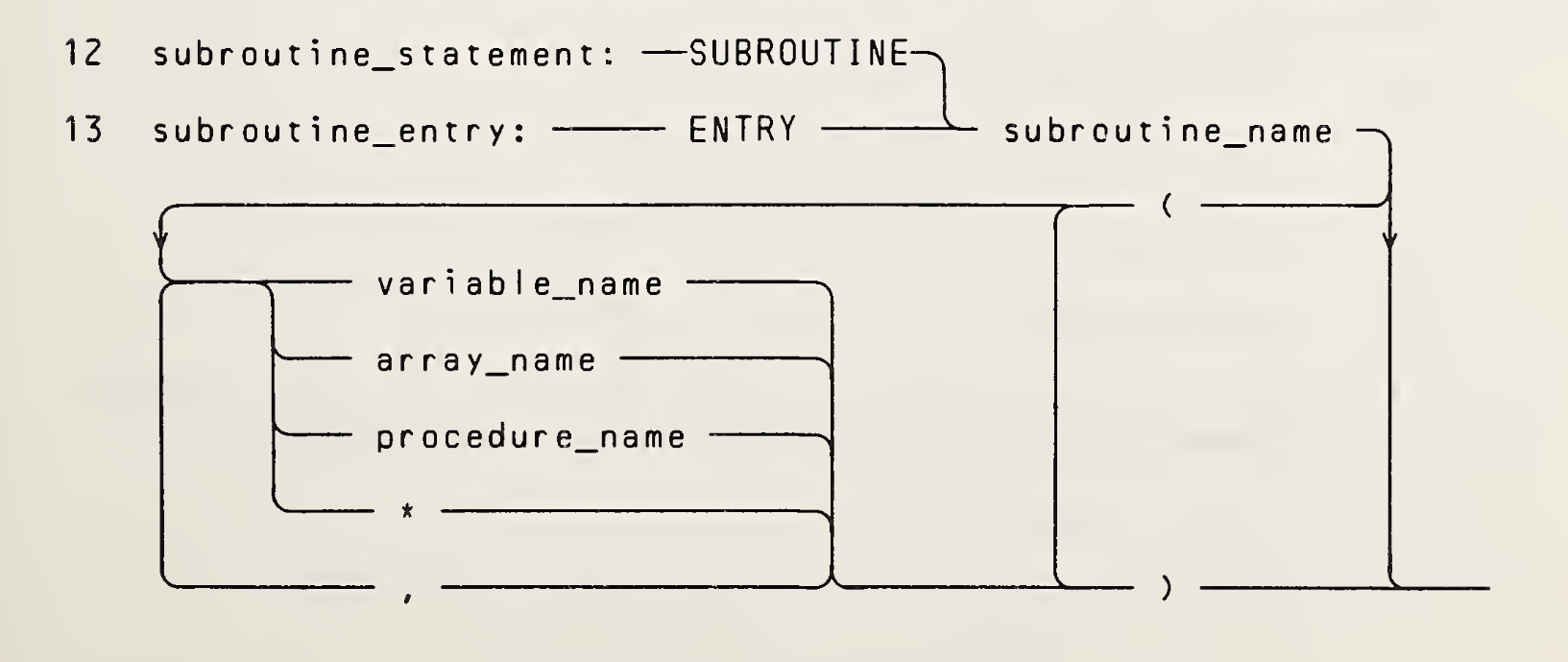
For example the standard defines the grammar of the SUBROUTINE statement as:
SUBROUTINE sub [( [d [,d]...] )]where:
- sub is the symbolic name of the subroutine subprogram in which the SUBROUTINE statement appears. sub is a subroutine name.
- d is a variable name, array name, or dummy procedure name, or is an asterisk (15.9.3.5). d is a dummy argument.
and represents it visually as:
Nowadays it’s common to define grammars with BNF. That “B” is John Backus who led the invention of FORTRAN in 1954. Lessons learned from that project informed the development of BNF for the ALGOL language a few years later. BNF was eventually adopted by Fortran 90.
I implemented f2rust with the rust-peg parser generator,
primarily based on the railroad diagrams (verified against the prose).
Rules are defined recursively as patterns over characters
(no need for a separate lexing pass, which wouldn’t really make sense for FORTRAN’s syntax),
with inline Rust code that can construct arbitrary types:
parser!
Even at this early stage we run into questions about how strictly to follow the standards.
FORTRAN 77 says symbols have a maximum length of 6 characters.
The SPICE Toolkit largely sticks to this restriction,
which leads to some pretty cryptic function names
(e.g. CCIFRM = “frame Class and Class Id to FRaMe id and name”).
But SPICE also has ‘private’ APIs which are typically ZZ followed by
a 6-character name,
exceeding the standard’s limit.
(F77 has no concept of modules or namespaces or symbol visibility,
so there wasn’t a better option for private APIs.)
Fortran 90 expands the maximum length to 31, and strangely defines underscore as “alphanumeric” so it’s allowed in symbol names. SPICE avoids underscores in its core code but does use a few in test code.
A strict F77 compiler would reject these,
but fortunately there’s no need for f2rust to be strict;
nobody is going to be writing FORTRAN code specifically for f2rust
and then expecting it to be portable,
so there’s no harm in supporting a superset of the language
with unlimited-length symbols.
Another quirk is that FORTRAN defines arithmetic expressions with a left-recursive grammar
that permits expressions like A ** (-B) but not A ** -B.
Left-recursion is a problem for PEG parsers
so we can’t directly implement the standard’s grammar.
rust-peg has built-in support for expressions with operator precedence,
which works well here,
except it does allow A ** -B.
As it happens, real FORTRAN compilers like gfortran also allow it
(with a warning “Extension: Unary operator following arithmetic operator (use parentheses)”),
so it seems fine for f2rust to accept a superset of expressions too.
Ambiguity
FORTRAN’s keywords are not reserved words – users are free to reuse them as variable names.
For example the line END DO is the end of a loop, but the line END DO = 1 is an assignment
to the variable named ENDDO (remember that whitespace is ignored).
PEG parsers are greedy: when given a choice between multiple rules, they will accept the
first one that matches and will never backtrack.
So we need to be a little careful to avoid matching a keyword
that turns out to be the prefix of an assignment statement;
we parse one line at a time and each statement rule ends with the EOF marker ![_]
to ensure it matches the whole line.
There are some trickier cases of ambiguous grammar. For example, FORTRAN has statement functions which are a little bit like C macros – single-line functions defined inside another function:
SUBROUTINE TEST1()
INTEGER X
INTEGER Y
INTEGER ADD
(X) = X + Y
PRINT *, (5)
END
ADD(X) = X + Y is defining a statement function that takes an INTEGER argument and returns an INTEGER.
As with C macros, it’s allowed to access symbols like Y from the outer subroutine.
Unlike C it’s not just text substitution,
so you don’t need to go crazy with parentheses like #define ADD(x) ((x) + (y)).
But compare this almost-identical function:
SUBROUTINE TEST2()
INTEGER X
INTEGER Y
INTEGER (10)
(X) = X + Y
PRINT *, (5)
END
Now ADD is an array, and ADD(X) = X + Y is an assignment to the Xth element of the array.
Also the PRINT *, ADD(5) is performing a function call in the first example,
but reading an array element in the second example.
This means it’s impossible to fully parse a statement in isolation.
We can only disambiguate it by checking whether ADD was declared as a scalar type or an array.
In f2rust the grammar parser simply outputs ambiguous types like Expression::ArrayElementOrFunction and
the next phase of the compiler will figure out what it means.
Abstract syntax tree
Now that we’ve parsed all the statements individually,
we need to do function-level processing: set up a symbol table,
use that to resolve the ambiguous grammar,
and convert the function’s control flow statements
(SUBROUTINE..END DO..END DO, IF..ELSE..END IF, etc)
into a tree structure.
The symbol table contains the declared type and array dimensions of every symbol,
but it also contains a bunch of extra information that will help later with Rust code generation.
For example we’d like to convert the DO I = 1, NDIM loop into idiomatic-ish Rust like
for I in 1..=NDIM { ... }.
But this isn’t always possible: FORTRAN allows references to I
after the loop has ended (where it’ll have value NDIM+1), and Rust doesn’t.
So we track the stack of DO variables that are currently in scope,
and if they’re ever accessed out of scope
we set a flag in the symbol table to force uglier code generation.
For example this code:
INTEGER I, J, N
C Basic loop
I = 1, 10
N = N + I
END DO
C Step by 2 per iteration
I = 1, 10, 2
N = N + I
END DO
C Loop variable is accessed after the loop
J = 1, 10, 3
N = N + J
END DO
C Now J == 13
N = N + J
is translated into:
let mut J: i32 = 0;
let mut N: i32 = 0;
for I in 1..=10
// Custom iterator, similar to Iterator::step_by()
// but also supports negative steps
for I in range
// Explicit implementation of FORTRAN's loop semantics.
// In particular the loop parameters are evaluated once
// at the start of the loop, not every iteration
N = ;
Fortunately FORTRAN forbids assigning to the loop variable from inside the loop, so we don’t need to worry about handling that case.
The rest of the AST construction is quite straightforward.
Global analysis
As discussed before, FORTRAN treats every argument as pass-by-mutable-reference,
and we want to convert that into a much more Rust-like API.
For example we can use &T instead of &mut T if the function
never actually tries to mutate the value.
But to determine that,
we can’t just look at the function in isolation;
it might pass the argument into another function that mutates it.
To handle this, we parse every file in the whole program into ASTs, do some symbol resolution to find what calls what, and propagate mutation flags up and down the call tree.
We also track whether a function (or anything below it in the call tree) performs IO,
in which case it should return Result<T> instead of T,
so we can use Rust’s normal error-handling mechanism to propagate IO errors up to the API user.
Similarly FORTRAN’s STOP statement, which terminates the process,
is converted into a Result return so it can be cleanly handled by the API user in a potentially multithreaded program.
Function pointers
FORTRAN supports function pointers, called dummy procedures. For example you can write:
SUBROUTINE PRINT ()
INTEGER I
PRINT *, I
END
SUBROUTINE INC ()
INTEGER I
I = I + 1
END
SUBROUTINE TWICE ()
EXTERNAL F
INTEGER I
CALL (I)
CALL (I)
END
PROGRAM MAIN
END
MAIN will increment N twice, then print it twice.
This is a headache for our global analysis.
As described earlier,
looking at whether an argument is actually mutated by a function,
we’d compile these into fn PRINT(i: &i32) and fn INC(i: &mut i32).
But then they’d have different function pointer types,
so it would be impossible to pass both into the same definition of TWICE.
To solve this, we associate each dummy procedure with every actual procedure
it could ever be called with,
based on our knowledge of every CALL statement in the program.
So TWICE’s dummy argument F is associated with the set {INC, PRINT}.
Then we perform unification. (Maybe not technically the correct term, but it’ll do).
If at least one of the actual procedures mutates
the argument, then the dummy procedure must declare that argument with mut,
and every actual procedure associated with it must also declare with mut.
This means PRINT will use mut despite never mutating the value itself.
Similarly, if one actual procedure performs IO (like PRINT) and returns Result,
every associated actual procedure must be declared as returning Result.
Information goes both up and down the call tree:
the mutability of I goes from INC up to TWICE and back down to PRINT.
In general it may go up and down multiple times.
Rather than implementing a fancy graph algorithm to track all of this efficiently,
f2rust takes a cruder approach:
iterate over every function,
propagate information up and down by a single level,
then go back to the start and repeat until there are no changes left to propagate.
There is a lot of redundant processing,
but in practice it’s easily fast enough for a codebase the size of SPICE.
The above example gets translated into:
which is far from idiomatic Rust (you’d probably prefer generics over function pointers) but seems reasonable as a direct translation of the FORTRAN.
Code generation
Finally we reach the code generation stage.
We use the AST plus the information from the global analysis,
to string-concatenate fragments of Rust code and build up the whole program.
(Maybe it would be cleaner to generate a proper Rust AST and serialise that,
but strings is easier and I didn’t have the energy to refactor it all.
We can let rustfmt tidy up some of the issues from crude non-context-aware string concatenation,
like redundant parentheses.)
One important step is to decide on the Rust type for each symbol.
If it’s a dummy argument and it’s mutated and has dimensions,
it’s a DummyArrayMut<T>.
If it’s a local non-array CHARACTER variable,
it’s a Vec<u8>.
We distinguish about twenty different types.
Each symbol will be used in many different contexts.
When a symbol name with type DummyArrayMut<T> is used in a Rust function signature,
we’ll emit name: &mut [T].
When passed as a scalar argument to another function,
it’s *name.first()
(bearing in mind that FORTRAN scalars are essentially arrays of size 1,
but in Rust they have distinct types so we need to explicitly convert).
There’s about a dozen different contexts,
and we need to handle every symbol type in every context,
so quite a few cases to work through.
Type conversions
Code generation is also where we handle FORTRAN’s implicit type conversion. Say we have the code:
INTEGER I
REAL R
DOUBLE PRECISION D
I = 1.5
R = I + 2.5
D = R + 3.5D0
Assignment to numeric types will implicitly convert the value,
so I = 1.5 becomes I = INT(1.5) or I = 1.
Binary operators will convert the ‘lesser’ operand to the greater type,
where INTEGER < REAL < DOUBLE. So I + 2.5 becomes REAL(I) + 2.5,
and R + 3.5D0 becomes DBLE(R) + 3.5D0.
Rust doesn’t do implicit type conversions, so we detect these cases and emit explicit conversions.
One random Rust quirk is that you can write e.g.
(2 as f64 > 1.0) but you cannot write (2 as f64 < 1.0),
because that is greedily parsed as casting to a generic type f64<1.0, ...>.
Fortunately rustc’s error message explains exactly why it got confused,
and it’s easily fixed with more parentheses.
Anyway, code generation is full of special cases like this,
choosing what Rust code to emit that will be both correct
and reasonably idiomatic.
The generated code for every function is collected in a new crate,
linked with a small runtime crate (f2rust_std) that implements helper types like DummyArrayMut
and features like IO,
and then you’re done.
Now we’ve given an overview of the whole compiler, we can dive deeper into some extra details of FORTRAN. Proceed to part 2.